
How to avoid CAPTCHA in web scraping?
AUGUST 31, 2023
CAPTCHAs—the bane of every web scraper's existence. If you're a developer who's ever tried to automate anything online, you've likely been stopped in your tracks by these pesky puzzles. But what if I told you there's more to CAPTCHAs than meets the eye?
In this blog, we're diving deep into the world of CAPTCHAs, not just to understand their mechanics but to arm you with actionable strategies to outwit them.
What is CAPTCHA?
CAPTCHA stands for "Completely Automated Public Turing Test to Tell Computers and Humans Apart." At its core, CAPTCHA is a security measure designed to differentiate genuine human users from automated scripts or bots. These tests are commonly encountered when purchasing products online, logging into websites, or signing up for new online accounts.
Why are CAPTCHAs used?
CAPTCHAs serve as a digital fortress, protecting websites from potential threats. Their primary objectives include:
Security: They prevent automated attacks, such as DDoS attacks, which can cripple websites.
Preventing Spam: By blocking bots, CAPTCHAs reduce unwanted spam on forums, comment sections, and feedback forms.
Safeguarding Data: They act as barriers against automated data harvesting tools, ensuring that sensitive data remains secure.
How do CAPTCHAs work?
CAPTCHAs function as a security measure by posing straightforward challenges for humans but difficult for automated bots. For developers, this involves implementing both client-side and server-side logic. The user encounters the CAPTCHA challenge on the client side, usually embedded in a form they must fill out. On the server side, the submitted answer is verified for accuracy.
The challenges often exploit the limitations of machine learning algorithms in tasks like distorted text recognition or object identification in images. This makes CAPTCHAs effective in preventing unwanted automated activities like form spamming or web scraping. Developers must carefully calibrate the CAPTCHA's complexity to ensure it's tough enough to deter bots but not so tricky that it alienates legitimate users. Additionally, modern CAPTCHAs often offer alternative formats, such as audio challenges, to accommodate users with disabilities, adding another layer of complexity to their implementation.
Types of CAPTCHAs
Distorted Text
CAPTCHAs often present distorted characters in images, requiring users to type them into a provided field. This type of CAPTCHA is relatively easy to implement and has been around for a long time. It's often used in form submissions to prevent automated bots from spamming. However, distorted text CAPTCHAs are becoming less effective as machine learning algorithms improve at optical character recognition (OCR). Therefore, they are often used in combination with other types of CAPTCHAs for enhanced security.

Image Recognition
Users might be asked to select all images with a specific object, like traffic lights or bicycles. This type of CAPTCHA is more complex to implement but offers better security against bots. It leverages the human ability to recognize patterns and objects, which is still challenging for machines. Developers often use third-party services like Google's reCAPTCHA for this, providing the added benefit of continuously updated algorithms and challenges. Image recognition CAPTCHAs are commonly used in high-security applications like online banking.
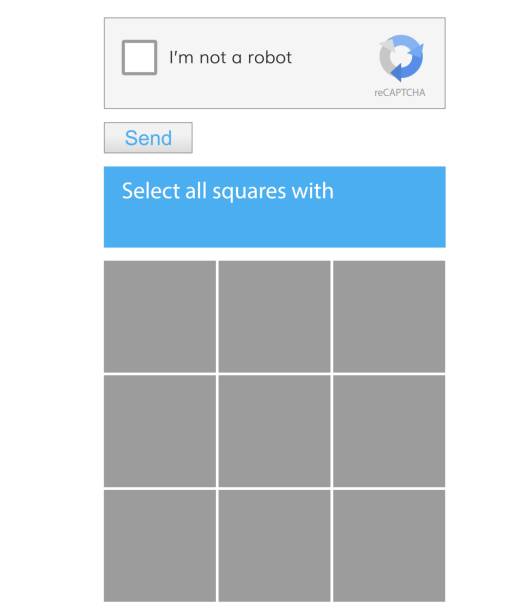
Audio Challenges
Some CAPTCHAs play a garbled audio clip and ask users to type out the spoken words. This type is beneficial for accessibility, allowing visually impaired users to bypass security measures. From a development standpoint, audio CAPTCHAs require additional audio processing and playback considerations, making them slightly more complex to implement. However, they are essential for making web services more inclusive. Like distorted text, audio challenges are often used with other CAPTCHA types to provide a multi-layered security approach.
Bypassing CAPTCHA: In-depth Techniques and Tips for Web Scrapers
Rotate IPs
Every device connected to the internet has a unique identifier known as an IP address. Websites monitor these addresses to identify unusual patterns, such as an IP sending a flurry of requests in quick succession. This behavior is typical of web scrapers and can lead to the IP being blacklisted. To counteract this, web scrapers can rotate or change their IP addresses.
This can be achieved using proxy services or Virtual Private Networks (VPNs). By regularly switching between different IPs, scrapers can mimic the behavior of multiple users, making it difficult for websites to pinpoint and block their activities.
Rotate User-Agent Strings
When users access a website, their browser sends a 'User-Agent' string to the server, providing details about the browser type, version, and operating system. Web scrapers, mainly if they use the exact User-Agent string repeatedly, can be easily detected. To camouflage their activities, scrapers should rotate between different User-Agent strings. This mimics the behavior of users accessing the site from other browsers and devices, making the scraper's activities blend in with regular web traffic.
Use a CAPTCHA Resolver
Encountering a CAPTCHA can halt a web scraping operation in its tracks. CAPTCHA resolvers, like 2Captcha or Anti-Captcha, are services designed to solve these challenges automatically. They employ machine learning algorithms and human solvers to decode and solve CAPTCHAs, allowing the scraping process to continue. While they offer a level of convenience, it's essential to note that very complex CAPTCHAs might still pose a challenge, and relying solely on resolvers isn't always foolproof.
Avoid Hidden Traps
Some websites employ a cunning strategy to catch bots: they use 'honeypots'—invisible links or buttons that humans wouldn't see or interact with, but bots might.
When a bot interacts with a honeypot, it inadvertently reveals its identity, leading to it being flagged. Web scrapers should be designed to recognize and avoid these traps, ensuring they only interact with genuine elements on the page.
Simulate Human Behavior
The key difference between a human and a bot is behavior. While a bot might send requests methodically at regular intervals, humans interact more randomly. To appear more human-like, scrapers can occasionally introduce random delays between requests, scroll pages, and even simulate mouse movements. This erratic behavior makes it challenging for websites to distinguish the scraper from genuine human users.
Save Cookies
Websites store tiny data on users' browsers to remember their preferences and previous interactions. By saving and reusing these cookies, web scrapers can maintain a consistent session with the website, reducing the likelihood of being presented with a CAPTCHA. It gives the impression of a returning user, who can be less suspicious of websites.
Hide Automation Indicators
Modern browser automation tools are incredibly sophisticated but can sometimes leave traces that websites can detect. For instance, the presence of specific JavaScript variables or the absence of certain plugins can be a giveaway. Tools like Puppeteer and Playwright can be fine-tuned to operate in a stealth mode, minimizing these indicators and making the automated browser session indistinguishable from a regular user session.
Developing Your Solution
For those who prefer a hands-on approach:
Playwright: An open-source node library that provides a high-level API for automating browsers. It supports multiple browsers and offers functionalities that can help mimic human-like interactions.
Puppeteer: A node library developed by Chrome's team. It provides a rich set of features for web scraping and browser automation.
FAQs:
Why it's so hard to spot and bypass CAPTCHAs?
The dynamic nature of CAPTCHAs, combined with advanced algorithms and random generation, makes them a moving target for bots.
Can you solve CAPTCHAs automatically?
While automation tools exist, CAPTCHAs continuously evolve, making it a cat-and-mouse game.
Can reCAPTCHA be bypassed?
Bypassing reCAPTCHA is more challenging due to its advanced analysis algorithms, but with the proper techniques, it's possible.
Can a bot bypass CAPTCHA?
With the correct configurations and techniques, advanced bots can bypass specific CAPTCHAs, but it's an ongoing challenge.
Latest posts

A decade of mastery: Experience antidetect technology redesigned with Multilogin X

Unlocking the power of API testing with Postman

Exploring GitOps environment models for Kubernetes cluster management
Unlocking the Power of Automation in Support Tasks

What is WebRTC: Revolutionizing online communication